
When the Cloud Burns: The AWS UAE Data Center Disaster and the DR/BCP Lessons Everyone Keeps Ignoring


The images coming out of Dubai look like something from a war movie — because they are. Massive columns of black smoke rising over the skyline. Intercepted missiles streaking overhead. And buried in the chaos, something most people aren't talking about: Amazon's primary Middle East cloud infrastructure just got knocked offline by what are almost certainly Iranian missiles and drones.
This isn't a drill. This isn't a theoretical tabletop exercise. This is the scenario your DR/BCP plan was supposed to be written for — and most organizations in the region didn't have one.
What Actually Happened: A Technical Timeline
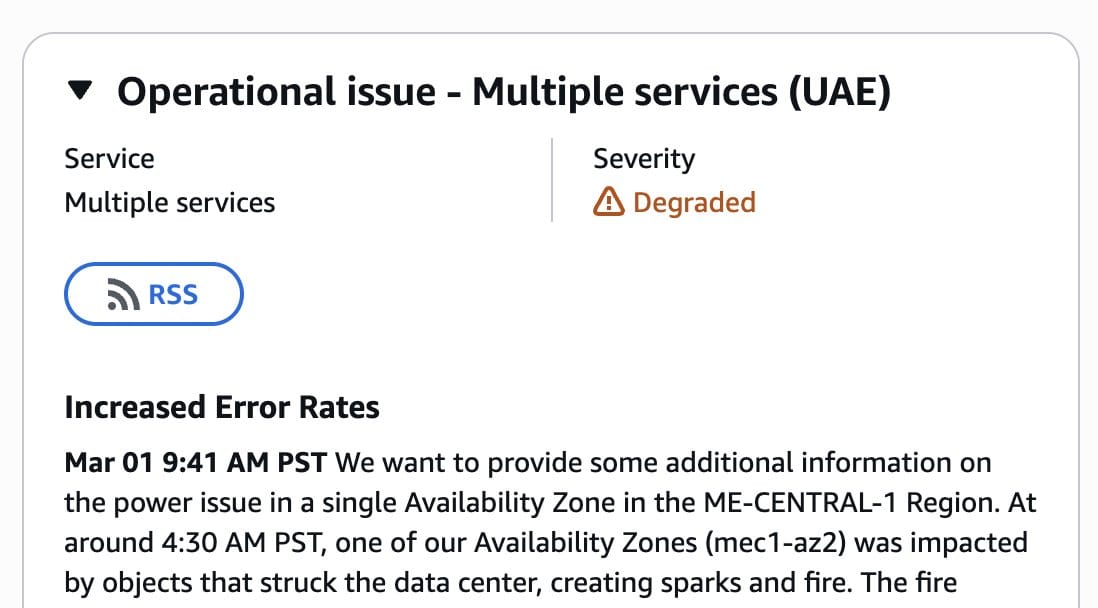
On Sunday, March 1, 2026, at approximately 4:30 AM PST (12:30 PM Dubai time), external objects struck an Amazon Web Services data center in the UAE's ME-CENTRAL-1 region. That corporate euphemism — "objects" — translates plainly: missiles or drone debris, during Iran's retaliatory strikes against Gulf states launched in response to the US-Israeli Operation Epic Fury that killed Ayatollah Ali Khamenei and multiple senior Iranian officials.
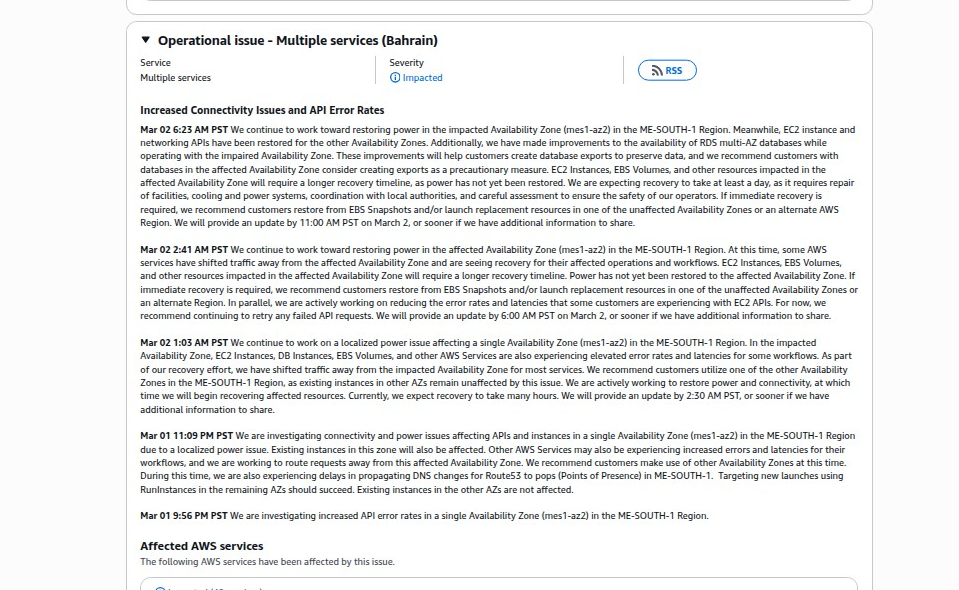
AWS confirmed in its health dashboard that availability zone mec1-az2 was hit, creating "sparks and fire." The fire department cut power to the entire facility — including backup generators — to fight the blaze.
Precise incident timeline (all times PST):
- 4:30 AM — External objects strike the mec1-az2 data center, fire breaks out
- 4:51 AM — AWS officially begins investigating connectivity and power issues
- 6:09 AM — AWS confirms localized power failure in mec1-az2; traffic weighting begins routing load to surviving AZs
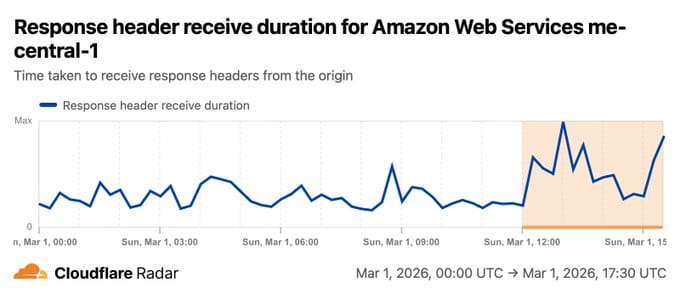
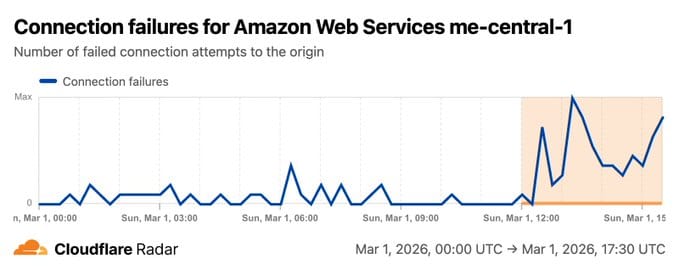
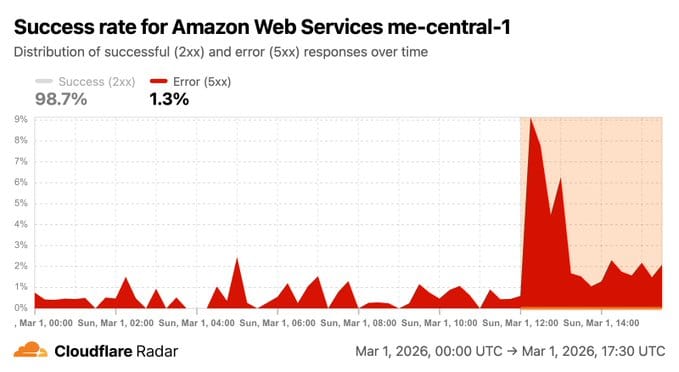
- ~12:00 PM UTC — Cloudflare Radar picks up visible spikes in error rates, connection failures, and response header receive times for ME-CENTRAL-1
- 2:28 PM PST — AllocateAddress API begins showing partial recovery
- ~Evening — AssociateAddress API degradation continues; AWS implements workaround allowing customers to detach Elastic IPs from affected resources and reassign to functioning zones
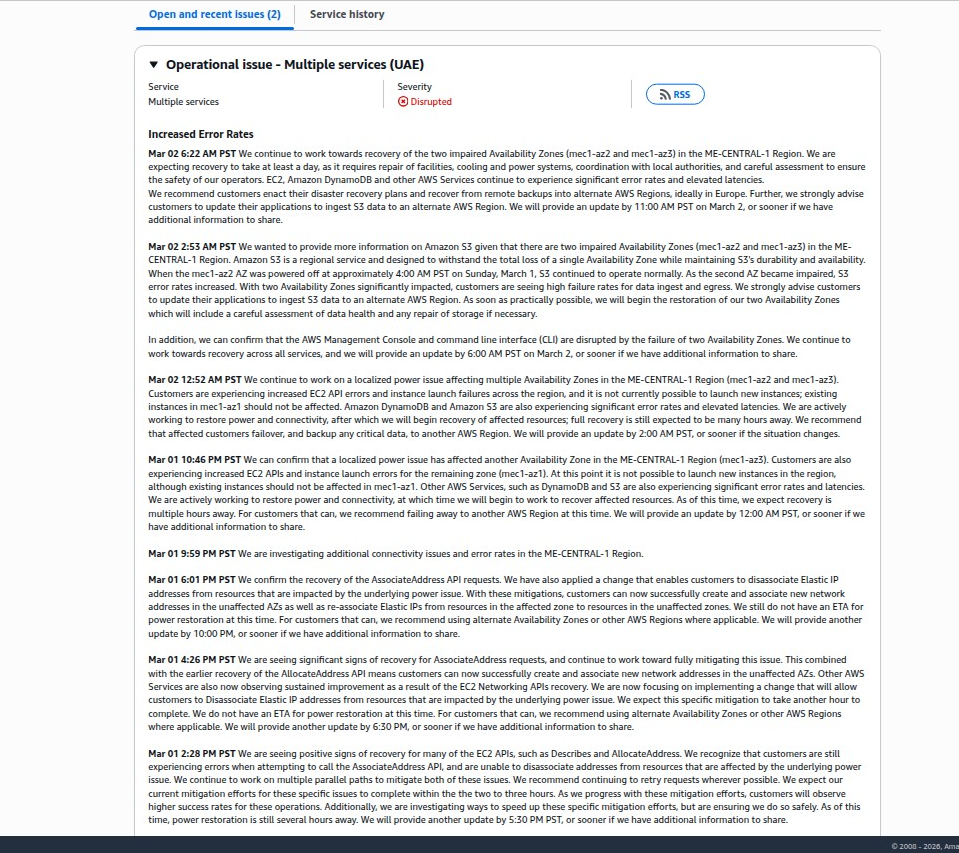
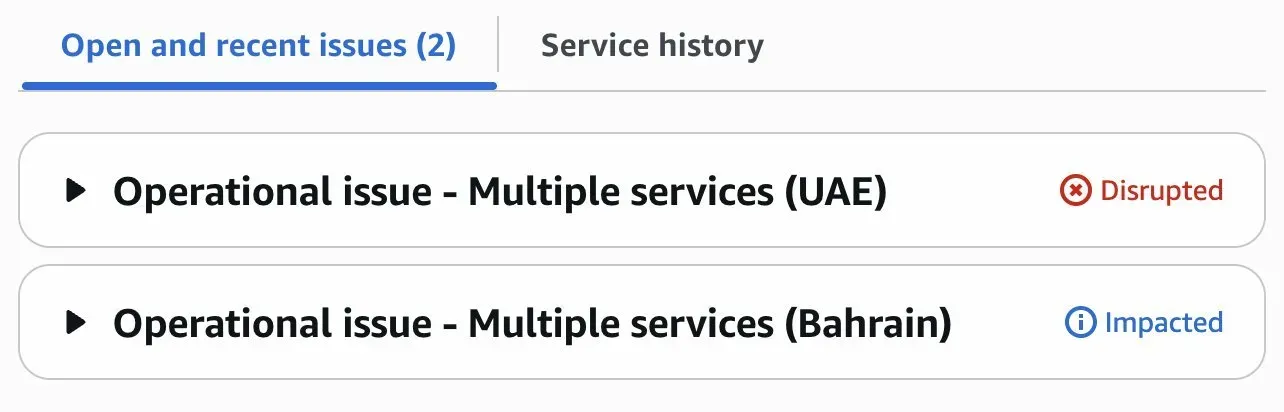
- Monday morning — Second availability zone (mec1-az3) goes offline; AWS status upgrades from "Degraded" to "Disrupted"
- Monday 2:53 AM PST — AWS confirms S3 is now actively failing with two AZs down: "customers are seeing high failure rates for data ingest and egress"
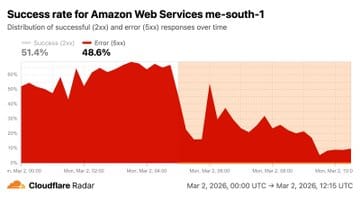
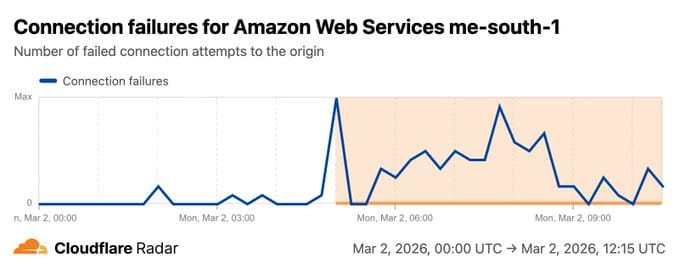
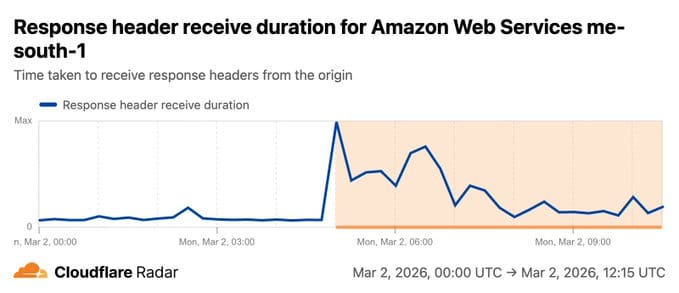
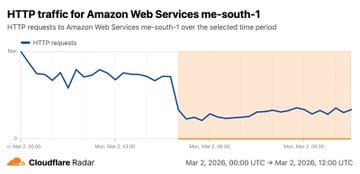
- Monday ~5:00 AM UTC — Cloudflare Radar ME-SOUTH-1 registers traffic drop-off, connection failures, and degraded response times for AWS Bahrain — a separate region now also impacted
That single power cutoff took down EC2 instances, EBS volumes, RDS databases, Lambda functions, EKS clusters, VPCs, and approximately 38 AWS services across ME-CENTRAL-1. Customers reported widespread throttling and failures on critical networking APIs: AllocateAddress, AssociateAddress, DescribeRouteTable, and DescribeNetworkInterfaces.
AWS's official recommendation to customers: enact disaster recovery plans and recover from remote backups into alternate AWS Regions — ideally in Europe. Recovery estimated at "at least a day" requiring physical repair of facilities, cooling systems, and power infrastructure, plus coordination with local authorities.
The Geopolitical Context You Can't Ignore
This didn't happen in a vacuum. Iran fired a reported 2 cruise missiles, 165 ballistic missiles, and over 540 drones across Gulf states in the surrounding hours. Airports, ports, and residential areas in Dubai, Abu Dhabi, Bahrain, and Qatar were struck. At least 15 casualties were reported across the UAE. The strikes were retaliatory — Iran's response to the assassination of its Supreme Leader.
AWS neither confirmed nor denied any connection to the Iranian strikes when directly asked by Reuters. Corporate language is what it is. The timeline and geography speak for themselves.
The wider conflict picture: US and Israeli forces continue operations. Iran has announced new waves of missiles from central Iran toward "enemy locations." Hezbollah has re-entered the fight from Lebanon. The Gulf states — UAE, Saudi Arabia, Qatar, Kuwait, Bahrain — repelled strikes but have not counterattacked. This is an active, escalating multi-theater conflict with no defined endpoint.
And cloud infrastructure sits right in the middle of it.



The DR/BCP/IR Failure Nobody Wants to Talk About
Here's the hard truth: physical risk has always been in scope for Disaster Recovery and Business Continuity Planning. We just stopped taking it seriously.
For the last decade, DR/BCP conversations have been dominated by ransomware, DDoS, power grid failures, and natural disasters. Geopolitical kinetic risk — actual physical strikes on infrastructure — got quietly shuffled to the theoretical column. Risk registers would note "armed conflict" as a low-probability event and move on. Organizations operating in the Gulf, serving Gulf customers, or depending on Gulf-region cloud infrastructure rarely war-gamed a scenario where the data center itself gets hit.
This week proved that was a mistake.
What the AWS ME-CENTRAL-1 Outage Exposed
1. Multi-AZ Is Not Multi-Region
AWS designed its availability zones to be physically separate and independently powered. When one AZ fails, the others continue — by design. That worked for about 12 hours. When mec1-az3 went down due to the broader conflict impacting regional power infrastructure, the multi-AZ redundancy model broke entirely. S3 — a service specifically engineered to withstand the total loss of a single AZ — began failing at scale once two zones were offline simultaneously.
Organizations that thought "we're multi-AZ, we're fine" discovered their apps were still going dark.
The lesson: Multi-AZ protects you from equipment failures and localized incidents. It does not protect you from a regional catastrophe.
2. Multi-Region Is the Actual Minimum for Critical Workloads
AWS explicitly told customers to failover to alternate regions — ideally Europe. Organizations that had cross-region replication configured, automated failover policies, and Route 53 health checks pointing at secondary regions recovered within minutes. Organizations that had never tested cross-region failover discovered their backup environments were months out of date, their runbooks were wrong, or their teams didn't know the procedures under pressure.
Your DR plan is only as good as the last time you tested it under realistic conditions. "We have backups in eu-west-1" is not a DR plan. It's a starting point.
3. Recovery Time Objectives Got Stress-Tested Against Physical Reality
AWS said recovery would take "at least a day" — requiring physical repair of facilities, cooling, and power systems, plus coordination with local authorities who controlled access to a fire-damaged building in an active conflict zone. That is not a software problem. That is a construction and logistics problem.
If your RTO for critical systems is measured in hours, and your single cloud region just declared a multi-day physical recovery window, you have a documented gap. For organizations in healthcare, finance, energy, or government contracting serving Gulf customers — RTO/RPO assumptions built around software failures don't account for the scenario where the building itself is damaged.
4. Your IR Plan Probably Doesn't Cover "Cloud Provider Tells You to Evacuate the Region"
Most IR plans have playbooks for: ransomware, DDoS, data breach, insider threat, vendor failure. Very few have a playbook for: "Your cloud provider just evacuated an entire geographic region and told you to move to another continent."
What does your call tree look like for that? Who has authority to invoke emergency spend to stand up infrastructure in a completely different region? Who holds the credentials? Who knows where the Terraform scripts are? Who can authorize the AWS cost spike from running a duplicate environment in eu-central-1 at 2 AM while your primary region is on fire?
If you don't have immediate answers to those questions, your IR plan has a gap.
5. Physical Security Risk Assessments Must Include Geopolitical Context
Standard physical security risk assessments for data centers cover access controls, perimeter security, power redundancy, and natural disaster risk. Missile strikes are in scope now — not as a future scenario, but as a documented, occurred event affecting Tier-1 cloud infrastructure operated by the largest cloud provider in the world.
If your organization operates in regions with active or elevated geopolitical conflict risk — and that list just got longer — your physical risk assessment needs to include proximity to military targets, the disruption radius of regional conflict, and the availability of cloud alternatives outside the conflict zone.

What AWS Customers in the Region Should Do Right Now
Immediate (next 24-48 hours):
- Check the AWS Health Dashboard for current ME-CENTRAL-1 and ME-SOUTH-1 status
- If running workloads in ME-CENTRAL-1 or ME-SOUTH-1, follow AWS's guidance to migrate to alternate regions (eu-west-1, eu-central-1, or us-east-1)
- Verify your S3 cross-region replication is intact — S3 is actively failing in ME-CENTRAL-1 with two AZs down
- Confirm your most recent RDS snapshots are accessible from a non-Middle East region
- Review Route 53 health checks and DNS failover configurations
Short-Term (next 30 days):
- Run a tabletop exercise specifically for "cloud region becomes unavailable for 72+ hours due to external physical event"
- Update your BCP to include geopolitical and kinetic risk scenarios for all regions where you operate
- Verify cross-region DR configurations are actually tested and documented — not just configured and forgotten
- Review vendor contracts for SLA implications when outages result from force majeure vs. AWS operational failures
- Leverage Cloudflare Radar Cloud Observatory for real-time independent visibility into cloud provider health — it detected both ME-CENTRAL-1 and ME-SOUTH-1 degradation in real time, independently of AWS's own status page
Strategic:
- Reassess whether single-cloud, single-region architectures are acceptable for your risk profile
- For workloads serving or operating in conflict-adjacent regions, evaluate active-active multi-region or multi-cloud architectures
- Add "geopolitical risk assessment" as a standing agenda item in your annual BCP review
- Confirm whether your cyber insurance covers losses from cloud outages caused by acts of war (most policies exclude this)
- Document the "region evacuation" runbook — who approves emergency cross-region spend, who has credentials, where the IaC scripts live
The Broader Warning for the Industry
AWS customers in UAE include major financial institutions — Dubai Islamic Bank, Al Ghurair Investment — and hundreds of regional enterprises. When ME-CENTRAL-1 went dark, it wasn't just apps going down. It was transactions failing, communications going offline, and operations grinding to a halt in the middle of an active military conflict where the internet was needed most.
This is the intersection of geopolitical risk, physical infrastructure security, and digital operational resilience that the security community has been theorizing about for years. It happened. In real time. Today.
Every CISO and CTO in the region — and every organization with supply chain, customer, or operational dependencies in the Gulf — should be answering these questions right now:
- Do we have workloads in ME-CENTRAL-1 or ME-SOUTH-1?
- Are those workloads replicated to a region outside the conflict zone?
- Have we actually tested failover, or do we just have backups sitting untouched?
- What is our RTO if our primary cloud region is physically compromised for 72+ hours?
- Does our IR plan cover the "leave the region" scenario?
If the answers aren't immediately clear, that is your action item.
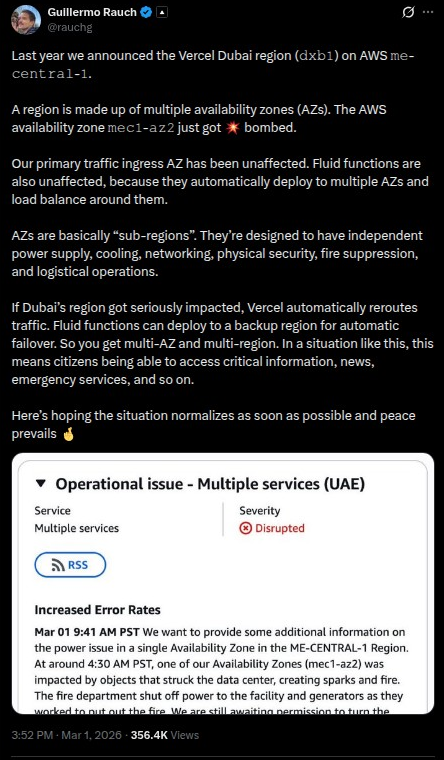
Update on 𝚍𝚡𝚋𝟷. The situation has worsened and it’s progressed into a full blown, multi-AZ outage.
— Guillermo Rauch (@rauchg) March 2, 2026
(Possibly first ever of its kind ever from a non-software root cause)
Many workloads on Vercel are global in nature. Routing Middleware for instance automatically deploys… https://t.co/TCNbRlJfaw

Final Thought
The cloud was supposed to eliminate physical infrastructure risk. We outsourced our servers to AWS, put our data in S3, and told ourselves the data center problem was someone else's problem now.
Today, Iranian missiles reminded us that someone else's data center is still a data center — with a physical address, a geographic location, and a blast radius.
DR/BCP isn't a checkbox. It's a living program that has to account for the world as it actually is — not just software failures and ransomware, but fire, power loss, physical damage, and yes, kinetic military conflict affecting critical infrastructure in regions where the cloud lives.
The organizations that tested their failover procedures, maintained current cross-region backups, and had documented runbooks for regional cloud outages are recovering today.
The ones that didn't are learning an expensive lesson.
Live monitoring resources:



